Paper Review: A ConvNet for the 2020s
Author: Zhuang Liu1,2*, Hanzi Mao1, Chao-Yuan Wu1, Christoph Feichtenhofer1, Trevor Darrell2, Saining Xie1†
Affiliation: 1Facebook AI Research (FAIR), 2UC Berkeley
Code: https://github.com/facebookresearch/ConvNeXt
Introduction
- Without the ConvNet inductive biases, a vanilla ViT model faces many challenges in being adopted as a generic vision backbone.
- Many of the advancements of Transformers for computer vision have been aimed at bringing back convolutions.
- The only reason ConvNets appear to be losing steam is that (hierarchical) Transformers surpass them in many vision tasks, and the performance difference is usually attributed to the superior scaling behavior of Transformers, with multi-head self-attention being the key component.
- Our research is intended to bridge the gap between the pre-ViT and post-ViT eras for ConvNets, as well as to test the limits of what a pure ConvNet can achieve.
- Key question: How do design decisions in Transformers impact ConvNets’ performance?
1. Macro design
1.1 Changing stage compute ratio
Following Swin Transformer’s design, the number of blocks in each stage is adjusted from (3, 4, 6, 3) to (3, 3, 9, s3)
1.2 Changing stem to “Patchify”
Swin Transformer uses a similar “patchify” layer, but with a smaller patch size of 4 to accommodate the architecture’s multi-stage design.
-> Replace the ResNet-style stem cell with a patchify layer implemented using a 4×4, stride 4 convolutional layer.
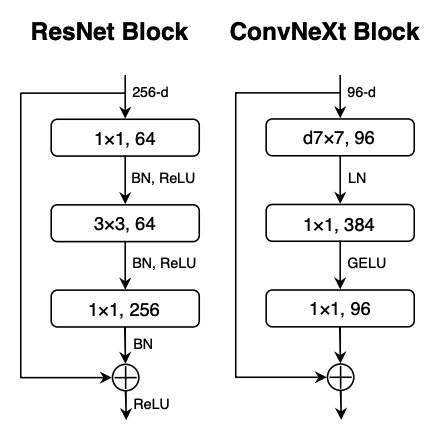
1.3 ResNeXt-ify
Use depthwise convolution and increase the network width to the same number of channels as Swin-T’s (from 64 to 96).
1.4 Inverted Bottleneck
One important design in every Transformer block is that it creates an inverted bottleneck, i.e., the hidden dimension of the MLP block is four times wider than the input dimension. (a,b)
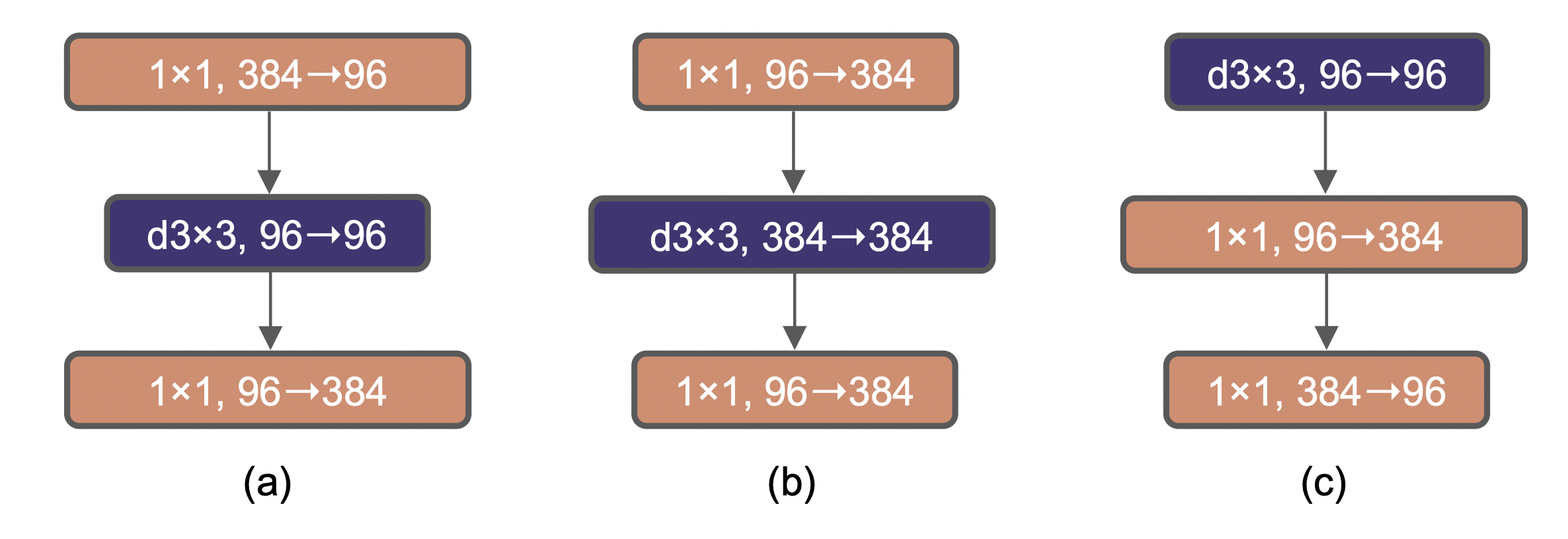
1.5 Large Kernel Sizes
- Moving up depthwise conv layer: That design decision is also evident in Transformers: the MSA block is placed prior to the MLP layers. (c)
- Increasing the kernel size: increase to 7x7
2. Micro design
2.1 Replacing ReLU with GELU
GELU is utilized in the most advanced Transformers, including Google’s BERT and OpenAI’s GPT-2, and, most recently, ViTs.
2.2 Fewer activation functions
Consider a Transformer block with key/query/value linear embedding layers, the projection layer, and two linear layers in an MLP block. There is only one activation function present in the MLP block.
2.3 Fewer normalization layers
Transformer blocks usually have fewer normalization layers.
2.4 Substituting BN with LN
LN has been used in Transformers, resulting in good performance across different application scenarios.
2.5 Separate downsampling layers
In Swin Transformers, a separate downsampling layer is added between stages. Several LN layers also used in Swin Transformers: one before each downsampling layer, one after the stem, and one after the final global average pooling.
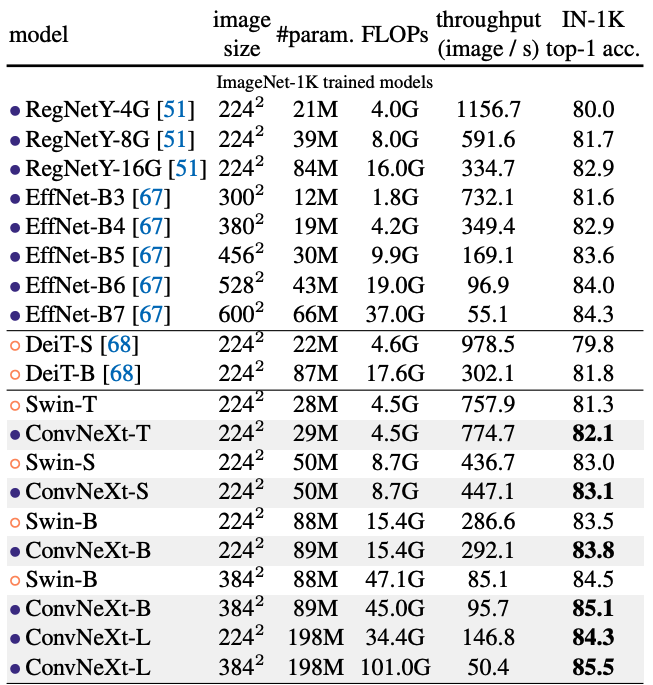
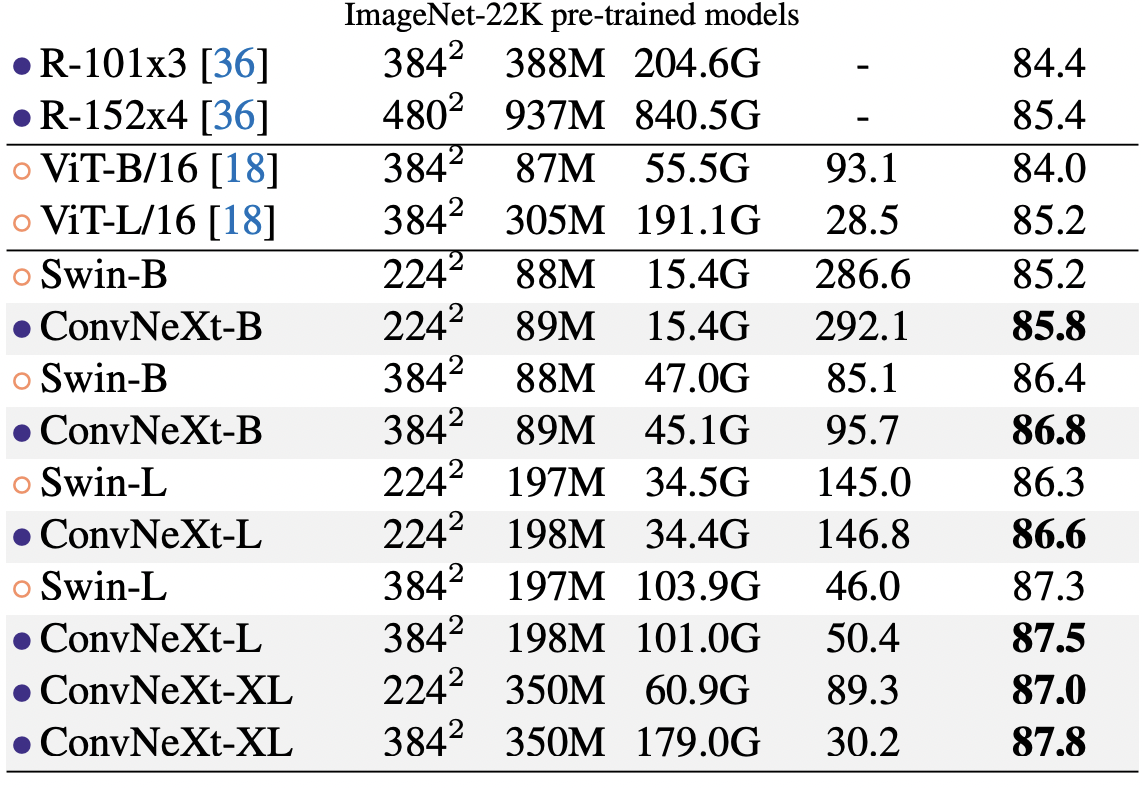
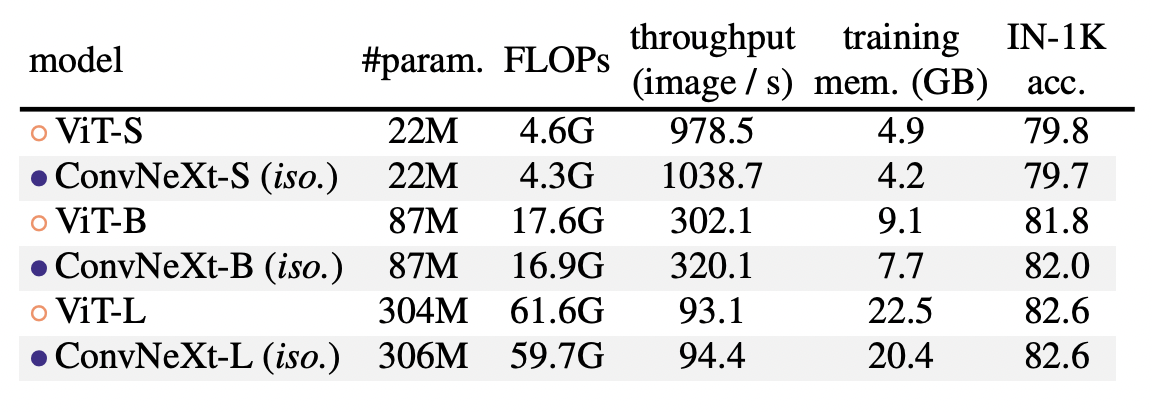
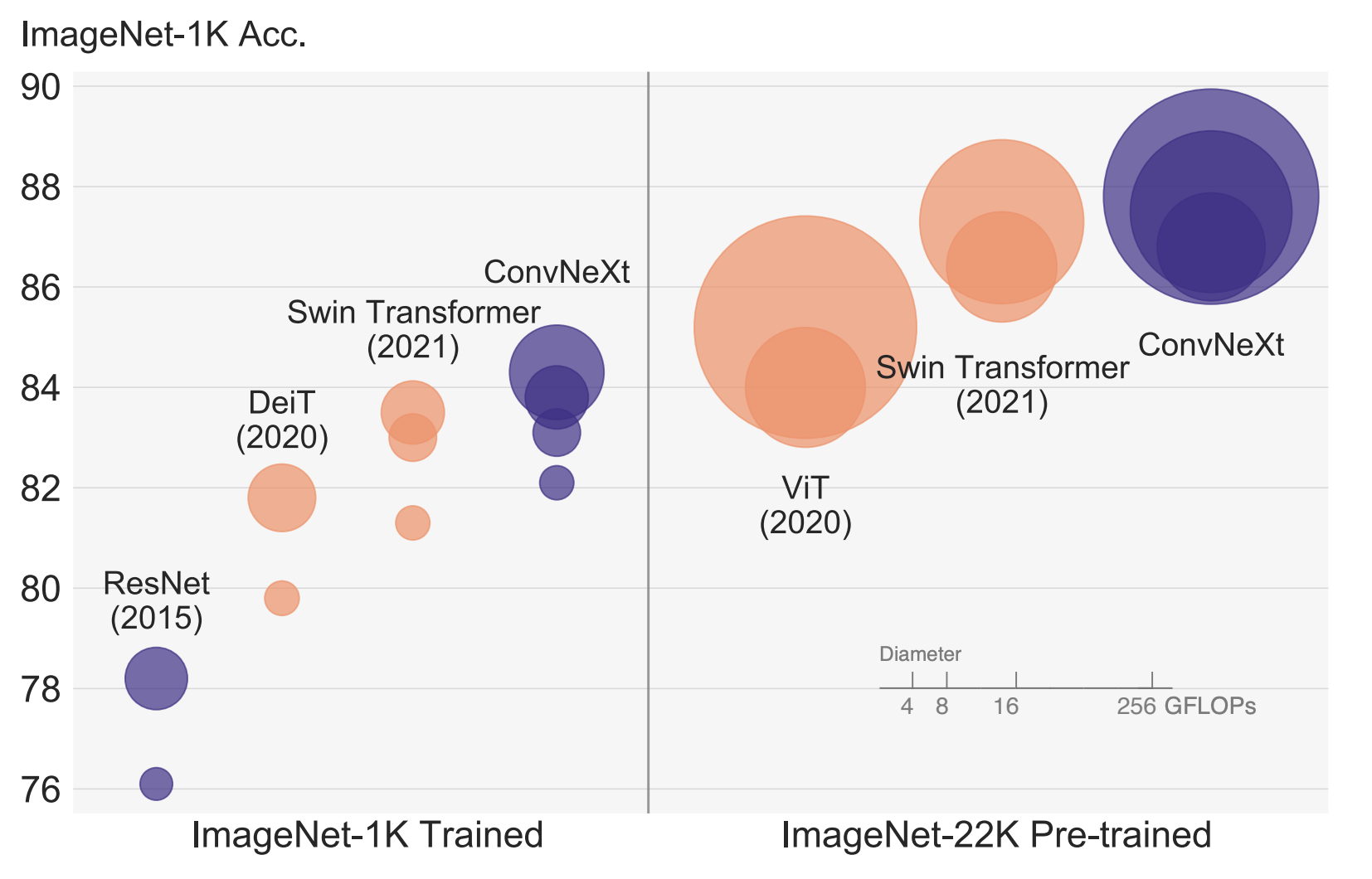
3. Experiment